In a previous blog post I had covered the motivation for needing a library like Netflix Hystrix. Here I will jump into some of the very basic ways to start using Hystrix and follow it up with more complex use cases.
A simple Hello World example of a "Hystrix Command" is the following:
The run method holds any dependent activity that we want to be protected against, which ultimately returns the parameterized type - String in this specific instance. If you are fan of Netflix Rx-java library , then another way to create the Hystrix command is the following:
Here "construct" method returns the Rx-java Observable.
Or, it can be made to return a Future :
Or, even better it can be made to return a Rx-Java observable:
The Observable variation of the command also works along the same lines, however we should contrast a small behavior difference:
There are two ways to obtain an Observable here, one is like the above by making an ".observe()" call, another is the following way:
another is the following using ".toObservable()" call :
The difference is that the ".observe()" method returns a Hot Observable which starts executing the "construct" method immediately, whereas the ".toObservable" variation returns a Cold Observable and would not call "construct" method unless it is subscribed to, say the following way:
I have more information here.
Note though that Hystrix Command is not a Singleton, the typical way to use Hystrix Command is to construct it where it is required and dispose it once done.
This parameter specifies a Hystrix "Command group" Key, along with Command Key which by default is the simple name of the class, it controls a lot of the bells and whistles of Hystrix behavior, a sample of the properties is the following and I will come back to the specifics of these later:
Another behavior we may want to control is the response in case the call to the dependent service fails, a fallback method provides this behavior, so consider a case where the dependent service always fails:
Here the dependent service call always fails and the response as shown in the following test will always be the response from the fallback method:
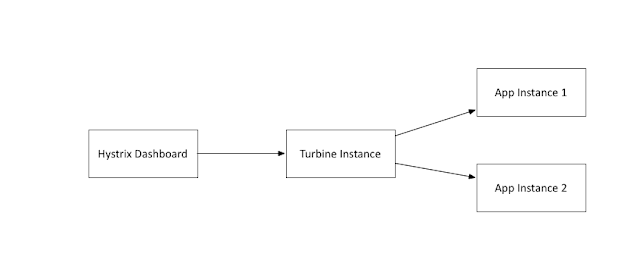
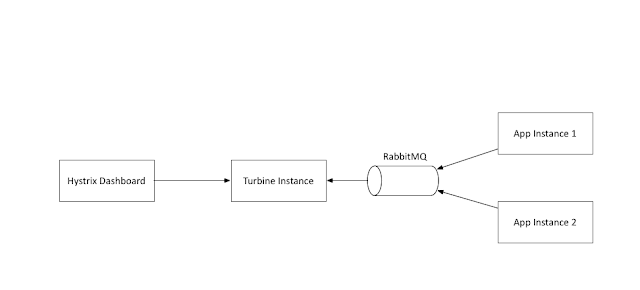
Since my demo is based on a Karyon2 Rx-Netty based application, my configuration can be seen here. The information from the Hystrix stream is a little too raw though, this is where the awesome Hystrix dashboard fits in - It consumes the Hystrix stream and shows real-time aggregated information about how each of the Hystrix command and different underlying threadpools are performing. I have here a sample Hystrix dashboard project based on the awesome Spring-Cloud project. A sample dashboard is here:
![]()
Hello World
A simple Hello World example of a "Hystrix Command" is the following:
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HelloWorldCommand extends HystrixCommand<String> {
private static final Logger logger = LoggerFactory.getLogger(HelloWorldCommand.class);
private final String name;
public HelloWorldCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("default"));
this.name = name;
}
@Override
protected String run() throws Exception {
logger.info("HelloWorld Command Invoked");
return "Hello " + name;
}
}
The run method holds any dependent activity that we want to be protected against, which ultimately returns the parameterized type - String in this specific instance. If you are fan of Netflix Rx-java library , then another way to create the Hystrix command is the following:
import com.netflix.hystrix.HystrixCommandGroupKey;
import com.netflix.hystrix.HystrixObservableCommand;
import rx.Observable;
public class HelloWorldObservableCommand extends HystrixObservableCommand<String> {
private String name;
public HelloWorldObservableCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("default"));
this.name = name;
}
@Override
protected Observable<String> resumeWithFallback() {
return Observable.just("Returning a Fallback");
}
@Override
protected Observable<String> construct() {
return Observable.just("Hello " + this.name);
}
}
Here "construct" method returns the Rx-java Observable.
Using a Hystrix Command
Now that we have a Hystrix command to wrap around our call, it can be used in whole lot of different ways, let us start with the simplest, in a synchronous call -HelloWorldCommand helloWorldCommand = new HelloWorldCommand("World");
assertEquals("Hello World", helloWorldCommand.execute());
Or, it can be made to return a Future :
HelloWorldCommand helloWorldCommand = new HelloWorldCommand("World");
Future future = helloWorldCommand.queue();
assertEquals("Hello World", future.get());
Or, even better it can be made to return a Rx-Java observable:
HelloWorldCommand helloWorldCommand = new HelloWorldCommand("World");
CountDownLatch l = new CountDownLatch(1);
Observable<String> obs = helloWorldCommand.observe();
obs.subscribe(
s -> logger.info("Received : " + s),
t -> logger.error(t.getMessage(), t),
() -> l.countDown()
);
l.await(5, TimeUnit.SECONDS);
The Observable variation of the command also works along the same lines, however we should contrast a small behavior difference:
HelloWorldObservableCommand helloWorldCommand = new HelloWorldObservableCommand("World");
logger.info("Completed executing HelloWorld Command");
Observable<String> obs = helloWorldCommand.observe();
There are two ways to obtain an Observable here, one is like the above by making an ".observe()" call, another is the following way:
HelloWorldObservableCommand helloWorldCommand = new HelloWorldObservableCommand("World");
Observable<String> obs = helloWorldCommand.toObservable();
another is the following using ".toObservable()" call :
HelloWorldObservableCommand helloWorldCommand = new HelloWorldObservableCommand("World");
Observable<String> obs = helloWorldCommand.toObservable();
The difference is that the ".observe()" method returns a Hot Observable which starts executing the "construct" method immediately, whereas the ".toObservable" variation returns a Cold Observable and would not call "construct" method unless it is subscribed to, say the following way:
CountDownLatch l = new CountDownLatch(1);
obs.subscribe(System.out::println, t -> l.countDown(), () -> l.countDown());
l.await();
I have more information here.
Note though that Hystrix Command is not a Singleton, the typical way to use Hystrix Command is to construct it where it is required and dispose it once done.
Fallback and Command Group Key
In the constructor of the HelloWorldCommand, I had called a super class constructor method with the following signature:public HelloWorldCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("default"));
this.name = name;
}
This parameter specifies a Hystrix "Command group" Key, along with Command Key which by default is the simple name of the class, it controls a lot of the bells and whistles of Hystrix behavior, a sample of the properties is the following and I will come back to the specifics of these later:
hystrix.command.HelloWorldCommand.metrics.rollingStats.timeInMilliseconds=10000
hystrix.command.HelloWorldCommand.execution.isolation.strategy=THREAD
hystrix.command.HelloWorldCommand.execution.isolation.thread.timeoutInMilliseconds=1000
hystrix.command.HelloWorldCommand.execution.isolation.semaphore.maxConcurrentRequests=10
hystrix.command.HelloWorldCommand.circuitBreaker.errorThresholdPercentage=50
hystrix.command.HelloWorldCommand.circuitBreaker.requestVolumeThreshold=20
hystrix.command.HelloWorldCommand.circuitBreaker.sleepWindowInMilliseconds=5000
hystrix.threadpool.default.coreSize=10
hystrix.threadpool.default.queueSizeRejectionThreshold=5
Another behavior we may want to control is the response in case the call to the dependent service fails, a fallback method provides this behavior, so consider a case where the dependent service always fails:
import com.netflix.hystrix.HystrixCommand;
import com.netflix.hystrix.HystrixCommandGroupKey;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class FallbackCommand extends HystrixCommand<String> {
private static final String COMMAND_GROUP="default";
private static final Logger logger = LoggerFactory.getLogger(FallbackCommand.class);
public FallbackCommand() {
super(HystrixCommandGroupKey.Factory.asKey(COMMAND_GROUP));
}
@Override
protected String run() throws Exception {
throw new RuntimeException("Always fail");
}
@Override
protected String getFallback() {
logger.info("About to fallback");
return "Falling back";
}
}
Here the dependent service call always fails and the response as shown in the following test will always be the response from the fallback method:
FallbackCommand fallbackCommand = new FallbackCommand();
assertEquals("Falling back", fallbackCommand.execute());
Monitoring
Before I wrap up the basics it is good to demonstrate an awesome feature that Hystrix packs in terms of Hystrix stream and Hystrix dashboard. Let us start with Hystrix streams, if enabled typically as a servlet in Java based webapplications, it provides a SSE stream of realtime statistics about the behavior of the Hystrix commands present in the web application.Since my demo is based on a Karyon2 Rx-Netty based application, my configuration can be seen here. The information from the Hystrix stream is a little too raw though, this is where the awesome Hystrix dashboard fits in - It consumes the Hystrix stream and shows real-time aggregated information about how each of the Hystrix command and different underlying threadpools are performing. I have here a sample Hystrix dashboard project based on the awesome Spring-Cloud project. A sample dashboard is here: