In the process of working on an automated Jenkins pipeline for deploying a Cloud Foundry application with two of my colleagues(Thanks Mark Alston, Dave Malone !) I decided to try my hand on writing a Gradle plugin to perform some of the tasks that are typically done using a command line Cloud Foundry Client.
Introducing the totally unimaginatively named "ya-cf-app-gradle-plugin" with a set of gradle tasks(dare I say opinionated!) that should help automate some of the routine steps involved in deploying a java application to a Cloud Foundry environment. The "ya" or the yet-another part is because this is just a stand-in plugin, the authoritative plugin for Cloud Foundry will ultimately reside with the excellent CF-Java-Client project.
I have provided an extensive README with the projects documentation that should help in getting started with using the plugin, the tasks should be fairly intuitive if you have previously worked with the CF cli.
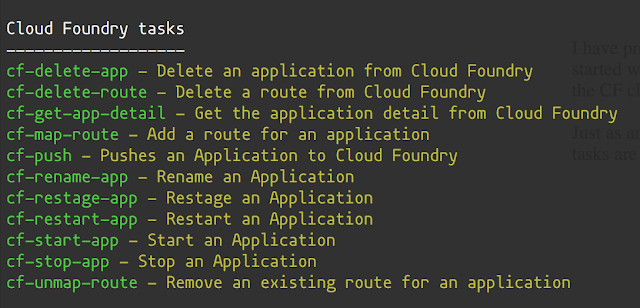
Just as an example, once the gradle plugin is cleanly added into the build script, the following gradle tasks are available when listed by running "./gradlew tasks" command:
![]()
All the tasks work off a configuration provided the following way in a cfConfig block in the buildscript:
Any overrides on top of the base configuration provided this way can be done by specifying gradle properties with a "cf.*" pattern. For eg. a normal push of an application would look like this:
and a push with the name of the application and the host name overridden would look like this:
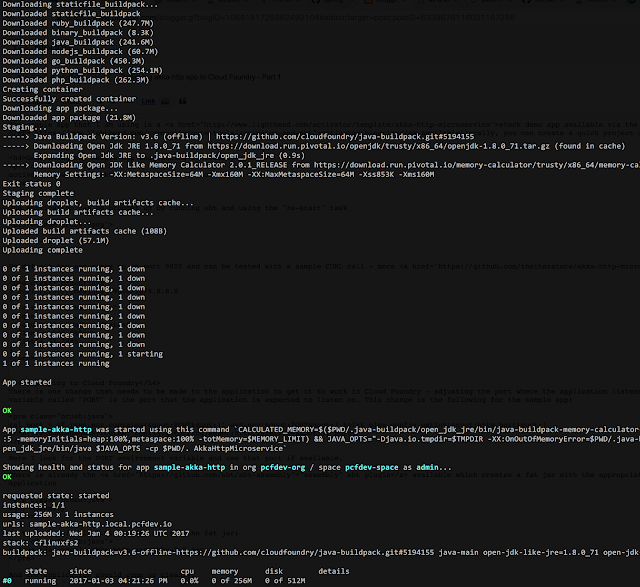
All of the tasks follow the exact same pattern, depending on the cfConfig block as the authoritative source of properties along with the command line overrides. There is one task that can be used for retrieving back some of the details of an app in CloudFoundry, the task is "cf-get-app-detail", say after deploying a canary instance of an app you wanted to run a quick test against it, the task would look along these lines, a structure "project.cfConfig" is populated with the app details once successfully invoked:
1. The plugin is built on top of the excellent CF-Java-Client project
2. I have borrowed a lot of ideas from gradle-cf-plugin but is more or less a clean room implementation
3. Here is a sample project which makes use of the plugin.
Introducing the totally unimaginatively named "ya-cf-app-gradle-plugin" with a set of gradle tasks(dare I say opinionated!) that should help automate some of the routine steps involved in deploying a java application to a Cloud Foundry environment. The "ya" or the yet-another part is because this is just a stand-in plugin, the authoritative plugin for Cloud Foundry will ultimately reside with the excellent CF-Java-Client project.
I have provided an extensive README with the projects documentation that should help in getting started with using the plugin, the tasks should be fairly intuitive if you have previously worked with the CF cli.
Just as an example, once the gradle plugin is cleanly added into the build script, the following gradle tasks are available when listed by running "./gradlew tasks" command:
All the tasks work off a configuration provided the following way in a cfConfig block in the buildscript:
apply plugin: 'cf-app'
cfConfig {
//CF Details
ccHost = "api.local.pcfdev.io"
ccUser = "admin"
ccPassword = "admin"
org = "pcfdev-org"
space = "pcfdev-space"
//App Details
name = "cf-show-env"
hostName = "cf-show-env"
filePath = "build/libs/cf-show-env-0.1.2-SNAPSHOT.jar"
path = ""
domain = "local.pcfdev.io"
instances = 2
memory = 512
//Env and services
buildpack = "https://github.com/cloudfoundry/java-buildpack.git"
environment = ["JAVA_OPTS": "-Djava.security.egd=file:/dev/./urandom", "SPRING_PROFILES_ACTIVE": "cloud"]
services = ["mydb"]
}
Any overrides on top of the base configuration provided this way can be done by specifying gradle properties with a "cf.*" pattern. For eg. a normal push of an application would look like this:
./gradlew cf-push
and a push with the name of the application and the host name overridden would look like this:
./gradlew cf-push -Pcf.name=Green -Pcf.hostName=demo-time-temp
All of the tasks follow the exact same pattern, depending on the cfConfig block as the authoritative source of properties along with the command line overrides. There is one task that can be used for retrieving back some of the details of an app in CloudFoundry, the task is "cf-get-app-detail", say after deploying a canary instance of an app you wanted to run a quick test against it, the task would look along these lines, a structure "project.cfConfig" is populated with the app details once successfully invoked:
task acceptanceTest(type: Test, dependsOn: "cf-get-app-detail") {
doFirst() {
systemProperty "url", "https://${project.cfConfig.applicationDetail.urls[0]}"
}
useJUnit {
includeCategories 'test.AcceptanceTest'
}
}
References:
1. The plugin is built on top of the excellent CF-Java-Client project
2. I have borrowed a lot of ideas from gradle-cf-plugin but is more or less a clean room implementation
3. Here is a sample project which makes use of the plugin.