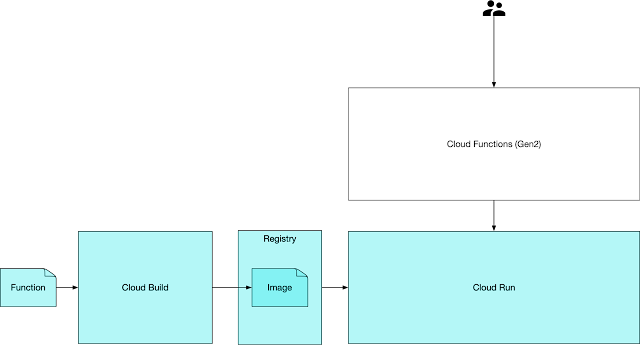
One advice for logging that I have seen when targeting applications to cloud platforms is to simply write to Standard Out and platform takes care of sending it to the appropriate log sinks. This mostly works except when it doesn't - it especially doesn't when analyzing failure scenarios. Typically for Java applications this means looking through a stack trace and each line of a stack trace is treated as a separate log entry by the log sinks, this creates these problems:
- Correlating multiple line of output as being part of a single stack trace
- Since applications are multi-threaded even related logs may not be in just the right order
- The severity of logs is not correctly determined and so does not find its way into the Error Reporting system
This post will go into a few approaches when logging from a Java application in Google Cloud Platform
Problem
Let me go over the problem once more, so say I were to log the following way in Java code:
LOGGER.info("Hello Logging")
And it shows up the following way in the GCP Logging console
{
"textPayload": "2022-04-29 22:00:12.057 INFO 1 --- [or-http-epoll-1] org.bk.web.GreetingsController : Hello Logging",
"insertId": "626c5fec0000e25a9b667889",
"resource": {
"type": "cloud_run_revision",
"labels": {
"service_name": "hello-cloud-run-sample",
"configuration_name": "hello-cloud-run-sample",
"project_id": "biju-altostrat-demo",
"revision_name": "hello-cloud-run-sample-00008-qow",
"location": "us-central1"
}
},
"timestamp": "2022-04-29T22:00:12.057946Z",
"labels": {
"instanceId": "instanceid"
},
"logName": "projects/myproject/logs/run.googleapis.com%2Fstdout",
"receiveTimestamp": "2022-04-29T22:00:12.077339403Z"
}
This looks reasonable. Now consider the case of logging in case of an error:
{
"textPayload": "\t\tat reactor.core.publisher.Operators$MultiSubscriptionSubscriber.onSubscribe(Operators.java:2068) ~[reactor-core-3.4.17.jar:3.4.17]",
"insertId": "626c619b00005956ab868f3f",
"resource": {
"type": "cloud_run_revision",
"labels": {
"revision_name": "hello-cloud-run-sample-00008-qow",
"project_id": "biju-altostrat-demo",
"location": "us-central1",
"configuration_name": "hello-cloud-run-sample",
"service_name": "hello-cloud-run-sample"
}
},
"timestamp": "2022-04-29T22:07:23.022870Z",
"labels": {
"instanceId": "0067430fbd3ad615324262b55e1604eb6acbd21e59fa5fadd15cb4e033adedd66031dba29e1b81d507872b2c3c6cd58a83a7f0794965f8c5f7a97507bb5b27fb33"
},
"logName": "projects/biju-altostrat-demo/logs/run.googleapis.com%2Fstdout",
"receiveTimestamp": "2022-04-29T22:07:23.317981870Z"
}
There would be multiple of these in the GCP logging console, for each line of the stack trace with no way to correlate them together. Additionally, there is no severity attached to these event and so the error would not end up with Google Cloud Error Reporting service.
Configuring Logging
<configuration>
<appender name="gcpLoggingAppender" class="com.google.cloud.logging.logback.LoggingAppender">
</appender>
<root level="INFO">
<appender-ref ref="gcpLoggingAppender"/>
</root>
</configuration>
<configuration>
<appender name="gcpLoggingAppender" class="com.google.cloud.logging.logback.LoggingAppender">
<redirectToStdout>true</redirectToStdout>
</appender>
<root level="INFO">
<appender-ref ref="gcpLoggingAppender"/>
</root>
</configuration>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<include resource="org/springframework/boot/logging/logback/console-appender.xml"/>
<appender name="gcpLoggingAppender" class="com.google.cloud.logging.logback.LoggingAppender">
<redirectToStdout>true</redirectToStdout>
</appender>
<root level="INFO">
<springProfile name="gcp">
<appender-ref ref="gcpLoggingAppender"/>
</springProfile>
<springProfile name="local">
<appender-ref ref="CONSOLE"/>
</springProfile>
</root>
</configuration>
This Works..But
<appender name="jsonLoggingAppender" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.contrib.json.classic.JsonLayout">
<jsonFormatter class="ch.qos.logback.contrib.jackson.JacksonJsonFormatter">
</jsonFormatter>
<timestampFormat>yyyy-MM-dd HH:mm:ss.SSS</timestampFormat>
<appendLineSeparator>true</appendLineSeparator>
</layout>
</appender>
package org.bk.logback.custom;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.spi.ILoggingEvent;
import ch.qos.logback.contrib.json.classic.JsonLayout;
import com.google.cloud.logging.Severity;
import java.util.Map;
public class GcpJsonLayout extends JsonLayout {
private static final String SEVERITY_FIELD = "severity";
@Override
protected void addCustomDataToJsonMap(Map<String, Object> map, ILoggingEvent event) {
map.put(SEVERITY_FIELD, severityFor(event.getLevel()));
}
private static Severity severityFor(Level level) {
return switch (level.toInt()) {
// TRACE
case 5000 -> Severity.DEBUG;
// DEBUG
case 10000 -> Severity.DEBUG;
// INFO
case 20000 -> Severity.INFO;
// WARNING
case 30000 -> Severity.WARNING;
// ERROR
case 40000 -> Severity.ERROR;
default -> Severity.DEFAULT;
};
}
}